Zoteroで日本語のCitation Keyを設定する
目次
ZoteroのBetter BibTeXプラグインで日本語のCitation Keyを生成する方法を紹介する。日本語を使うメリットは、日本語文献の場合に見やすくなることだ。注意点としては、データを扱うソフトがUTF-8に対応している必要がある。とはいえ、upBibTeXやBibLaTeX(biber)など新しいものはたいてい対応している。
Better BibTeXの設定 #
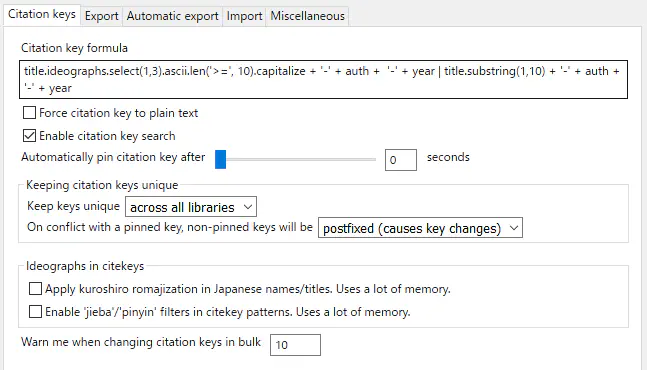
“Force citation key to plain text"のチェックを外す。オンにしていると強制的にローマ字(ASCII文字)に変換される。“Ideographs in citekeys"はデフォルトのままチェックしない。ローマ字化に関するオプションなので関係ない。
“Citation key formula"に以下のコードを貼りつける。コードの解説は後ほど。
title.ideographs.select(1,3).ascii.len('>=', 10).capitalize + '-' + auth + '-' + year | title.substring(1,10) + '-' + auth + '-' + year
生成されるCitation Key #
英語文献は「タイトルの最初の3単語(頭文字は大文字)-著者のラストネーム-出版年」となる。日本語文献は「タイトルの最初の10文字-著者のラストネーム-出版年」となる。
例えば”Spaced Repetition Promotes Efficient and Effective Learning“という論文であれば、“SpacedRepetitionPromotes-Kang-2016"となる。「認知心理学者が教える最適の学習法」という本は、“認知心理学者が教える-ワインスタイン-2022"となる。
Citation key formulaの解説 #
縦線|で区切ることで、2つのパターンを設定している。初めが英語文献のパターン、次が日本語文献のパターンだ。titleは文献タイトル、authは著者のラストネーム、yearは出版年だ。
英語文献のパターン #
title.ideographs.select(1,3).ascii.len('>=', 10).capitalize + '-' + auth + '-' + year
ideographsは日本語文字などを1単語として扱う。select(1,3)は先頭1番目から3つの単語を抽出する。asciiはASCII文字だけを抽出する。lenは文字列の長さが10文字以上であれば処理を続ける。10文字未満であれば次のパターンへスキップする。capitalizeは各単語の最初の文字を大文字にする。
まとめると、文献タイトルの先頭から3単語(日本語は1文字1単語とする)を取り出して、ASCII文字以外を取り除く。その文字列が10文字以上であれば英語文献、10文字以下であれば日本語文献として扱う。英語文献は頭文字を大文字にする。
日本語文献のパターン #
title.substring(1,10) + '-' + auth + '-' + year
substring(1,10)は文献タイトルの1番目の文字から、10文字を抽出する。